

Table des matières
Rechercher des fichiers
Au fil de tes aventures, il est extrêmement probable que tu aies besoin un jour de trouver un fichier précis sur le disque, que ce soit pour modifier une configuration, réparer une installation, etc…
Find
L’arme ultime dans ce genre de cas sera la commande find, qui permet de chercher précisément le fichier souhaité, en effectuant une recherche récursive dans l’ensemble des répertoires ciblés.
L’approche sera nécessairement un peu lente et dépendra de la taille du système… mais impossible de passer à côté de sa cible si bien utilisé, surtout si on combine l’outil avec des expressions régulières (regex, nous en reparlerons plus tard).
Pour chercher un fichier par son nom, utilise l’option -name et n’oublie pas de spécifier le répertoire de base pour lancer la recherche.
On note ici l’utilisation d’une wildcard (*) pour correspondre à tous les fichiers commençant par test.
N’oublie pas de créer quelques fichiers grâce à une boucle for et touch pour correctement illustrer l’exemple suivant.
for i in $(seq 1 3); do touch test$i; done
find /home -name "test*"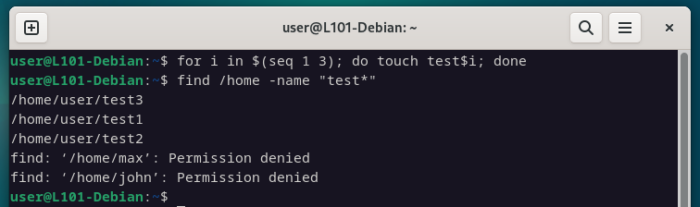
La première chose à noter, c’est que tous les fichiers créés ont été trouvés. Parfait.
La seconde chose intéressante, c’est que la commande find a essayé de parcourir l‘ensemble des répertoires présents dans /home, même ceux pour lesquels notre utilisateur n’a aucune permission… ce qui produit des messages d’erreurs liés aux permissions.
La commande ne te retournera pas forcément les mêmes résultats que nous suivant les expériences que tu as menées.
Tout dépendra des fichiers que tu as créés, des utilisateurs et/ou des permissions que tu as configurées, etc…
Retiens que chaque nouvelle ligne correspondra à un nouveau résultat/erreur et essaye de comprendre chacune de ces lignes.
La commande find est cependant bien plus puissante que ça… pour ce premier exemple, nous avons choisi de rechercher grâce au nom, mais il est possible d’agir suivant beaucoup d’autres propriétés, dont les permissions accordées.
Dans ce second exemple, utilise l’option -perm pour chercher tous les fichiers ayant les permissions indiquées.
Note qu’une valeur de 0 ne veux pas dire « aucune permission » mais « peu importe », donc /6000 correspondra à tous les fichiers qui ont des droits SUID et GUID (revoir la notation octale et les droits SUID/SGID si besoin).
N’oublie pas de créer un fichier avec les droits correspondants si ce n’est pas déjà fait, grâce à touch, chown et chmod, pour correctement illustrer l’exemple suivant.
touch test.sh
sudo chown 0:0 test.sh
sudo chmod 6755 test.sh
find /home -perm /6000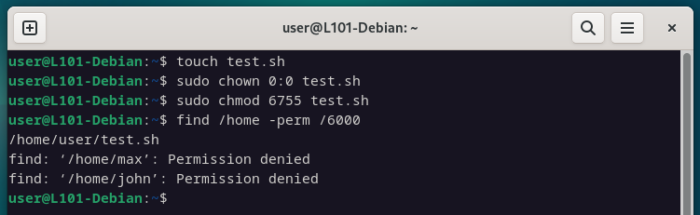
Locate et which
La commande locate permet de trouver des fichiers bien plus rapidement, mais est bien moins précise et flexible que find.
Elle repose sur une base de données qui indexe les fichiers du système périodiquement et optimise le procédé de recherche.
Cette base de donnée peut-être mise à jour manuellement en utilisant la commande updatedb, et c’est d’ailleurs obligatoire si l’on souhaite utiliser locate juste après son installation.
Si la commande locate n’est pas disponible sur ton système, installe-la grâce au gestionnaire de paquet, met à jour la base de donnée avec updatedb, puis lance ta recherche.
sudo apt install locate
updatedb
locate test1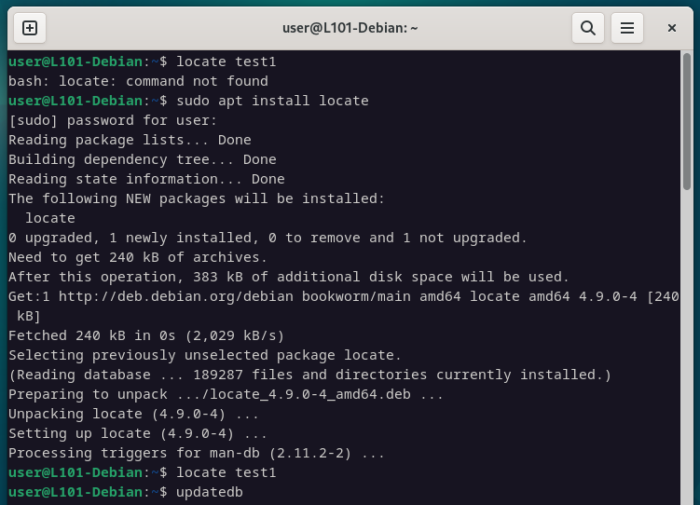
Une autre commande rapide est disponible avec which, qui permet de chercher les fichiers exécutables dans les répertoires du $PATH.
Son utilité principale est d’afficher le chemin absolu d’un binaire ou autre script disponible via le shell actuel.
which bash
Bonus
- Cherche une syntaxe te permettant de te débarrasser de toutes les erreurs de permissions lors de l’utilisation de find.
- Trouve tous les fichiers exécutables par ton utilisateur ayant des permissions SUID/SGID.
- Trouve tous les fichiers que ton utilisateur peut lire, et qui ont été modifiés dans les dernières 24 heures.
Obtenir de l’aide
Peu importe ce que tu fais avec ton système, il arrivera un moment où tu voudras avoir plus d’information sur une commande, une option, un format, un terme spécifique, etc…
La différence entre un bon et un mauvais utilisateur dans ce monde-là, c’est bien souvent la capacité à chercher et trouver les informations de manière efficiente.
Options help
Le moyen le plus rapide d’obtenir des infos sur une commande, ça reste de consulter les options d’aides mises à disposition par le développeur.
Bien que leur présence ne soit pas 100% garantie, commence toujours par essayer les options -h ou –help.
sudo -h
# ou
find --help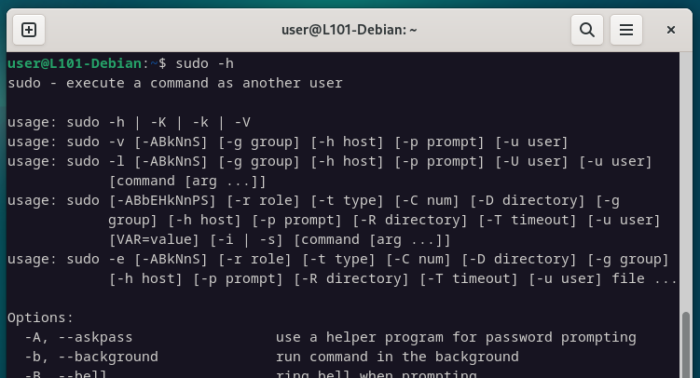
Attention tout de même aux faux amis… certaines commandes comme grep utilisent l’option -h pour d’autres choses spécifiques. Ou inversement.
Comme tu peux le constater, grep –help fonctionne correctement alors que grep -h non, et on trouve le détail dans l’aide affichée (l’option -h permet de ne pas afficher le préfixe du fichier).
grep --help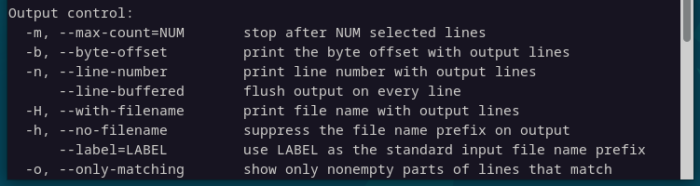
Man
La méthode la plus standardisée pour obtenir une documentation complète reste le manuel d’utilisation. Ils sont tous accessibles grâce à la commande man intégrée à votre système, et classent les pages suivant des catégories prédéfinies.
man grep
La majorité de ces manuels sont disponible sur des sites externes, ce qui est potentiellement plus facile à lire ou réutiliser (mais plus long à trouver).
Source : https://man7.org/linux/man-pages/dir_all_alphabetic.html
Sources externes
Certains programmes ou commandes sont assez complexes, et tu trouveras souvent des ressources directement sur les sites du développeur, des sites tiers contenant des guides (comme ici), ou sur le dépôt Git concerné.
Source : https://snapshooter.com/learn/linux/find
Fais tes propres recherches !

Si tu ne trouve pas ton bonheur dans ce genre de média, n’hésite pas également à élargir tes recherches via un moteur de recherche générique, et à arpenter les multiples forums et sites communautaires, pour trouver d’autres personnes avec le même problème que toi.
Attention ceci-dit, tout ce que tu trouves sur internet n’est pas une vérité absolue et certaines choses dépendent du contexte…
Donc ne lance pas des commandes au hasard sans avoir pris de précautions en amont (genre un snapshot de la VM ou une sauvegarde du fichier de configuration ciblé).
Source : https://stackoverflow.com/questions

La communauté
Bon… parfois, tout échoue et on arrive vraiment pas à utiliser un outil comme on l’aimerais.
A ce stade là, il est possible de se rendre sur un serveur Discord de la communauté (comme le notre !) pour poser ses questions DE FAÇON CONSTRUITE ET COMPLÈTE.
https://discord.com/invite/dfT5gUXdsm
Et on insiste là dessus… arriver dans une communauté pour demander « salu commen je fai pour utilisé docker ? » sans dire bonjour ou se présenter… c’est le meilleur moyen de se faire bannir en 3 minutes.
Prends le temps de décrire le problème que tu as, suivi des tentatives de résolution en incluant des screenshots des erreurs, puis donne les liens vers les guides/ressources utilisés.
Un confrère chevronné devrait pouvoir t’aider rapidement et la vie sera incroyable à nouveau.
Au passage, si tu veux creuser ce sujet, regarde cette vidéo, promis c’est utile.
Et pour finir, si vraiment rien ne va et que tu remets en doute tes choix de carrière à cause de cette foutue regex de mort…
Va chercher un copain de galère, de préférence qui comprendra ta douleur, et partagez vos peines autour d’un bon repas.
C’est pas ça qui va te donner la réponse à ta question, mais au moins vous passerez un bon moment et tu reviendras à ton problème la tête reposée…
Et c’est souvent ça qui amène à une illumination !
Bonus
- Exécute man man et profite de cette Inception.
- Viens nous dire bonjour sur le Discord HacktBack et rencontre la communauté !
- Pas d’exercice supplémentaire ici… tu vas devoir pratiquer à chaque fois que tu tombes sur un problème de toute façon…
Si tu te perds lors de tes aventures, reviens sur ce chapitre et assure-toi d’avoir essayé toutes ces étapes.

Les journaux d’événements
Kescesé ?
Les journaux d’événements (ou logs en anglais) sont des fichiers gardant une trace des erreurs ou événements produits par des programmes ou des services lors de leur exécution.
L’idée derrière les logs, c’est d’avoir un journal consultable par un utilisateur (le plus souvent un administrateur) pour pouvoir retracer un événement avec précision, souvent dans une démarche de diagnostic ou de compréhension.
La journalisation peut être assurée par divers composants, incluant les services (daemons) prévus par le système (anciennement syslogd ou le plus moderne systemd-journald), ou un service indépendant développé pour l’application.
Les fichiers de log
Allons vérifier le fichier de configuration du service de journalisation actuel, systemd-journald.
cat /etc/systemd/journald.conf
On remarque que ce fichier sert principalement à définir de quelle manière les logs vont être collectés, avec des paramètres temporels ou liés au stockage.
Savoir trouver et consulter les logs d’un système est essentiel pour obtenir des informations précises lors d’un diagnostic.
Sur un système Linux moderne, les logs seront situés par défaut dans le répertoire /var/log/, organisés par thématiques ou application.
ls /var/log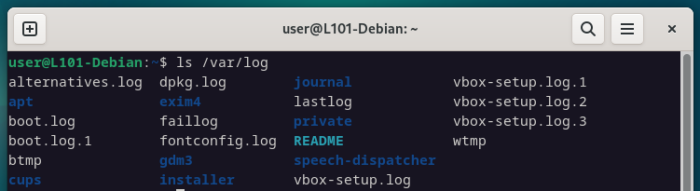
Les logs sont de simples fichiers textes et peuvent être ouverts ou traités comme n’importe quel autre fichier de ce type.
Prenons le fichier de log du gestionnaire de paquet APT pour exemple.
cat /var/log/apt/history.log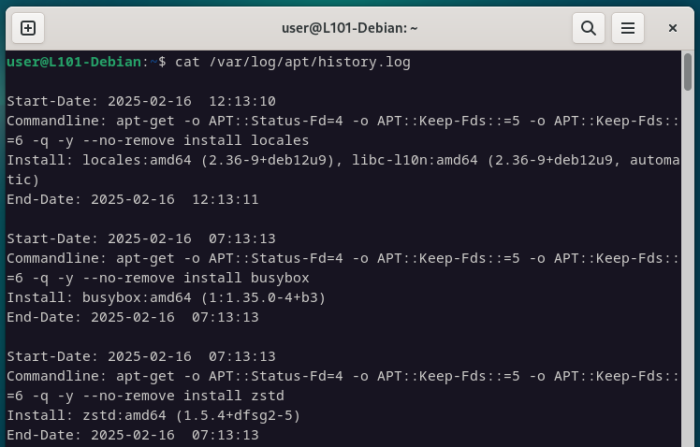
On remarque que toutes les installations de paquets depuis un certain temps sont tracées dans ce fichier, en partant du plus ancien jusqu’au plus récent.
Pour afficher les derniers événements en date, utilise la commande tail (pas de panique, on verra son utilisation dans le prochain cours).
Note qu’on peut retrouver précisément la dernière commande utilisée lors de l’installation de la commande locate en début de cours, avec l’horodatage précis et l’utilisateur en cause.
tail /var/log/apt/history.log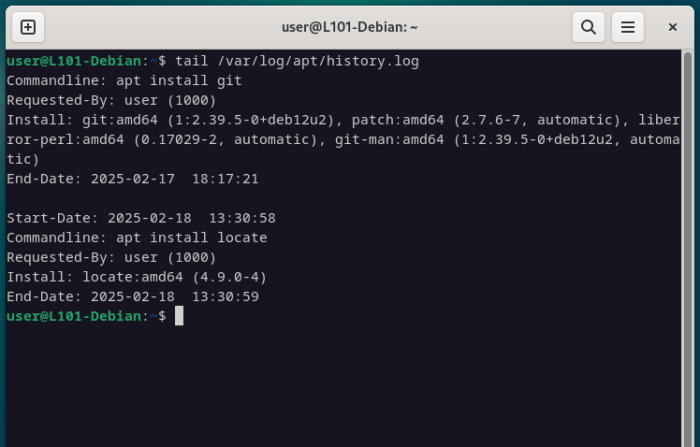
Journalctl
Pour consulter les logs systèmes de façon plus centralisée et plus moderne (donc via systemd), utilise la commande journalctl et ses différentes options.
journalctl
Il est possible de filtrer les logs par niveau, ou par programme cible, et de bien d’autres moyens.
Les guides d’utilisation sont nombreux, n’hésites pas à te balader sur des ressources créées par des administrateurs chevronnés pour prendre exemple sur leurs usages.
journalctl -p err
Source : https://blog.stephane-robert.info/docs/admin-serveurs/linux/journalisation/
Bonus
- Trouve les traces de ta dernière connexion dans les logs.
- Cherche à quoi correspondent les niveaux de logs (log levels) et quelle est leur utilité.
- Choisis un service spécifique et isole les logs d’erreur uniquement sur les dernières 24 heures.
Et la suite c’eeeeeeeeest… pas encore prêt.
On y travaille !