

Table des matières
Les variables
Les variables sont une notion commune à de nombreux langages de programmation, et on les retrouve également sans grande surprise dans notre shell et plus largement dans tous les systèmes d’exploitation.
Une variable est un élément qui permet de stocker une valeur sous un nom défini par l’utilisateur, pour être ré-utilisé lors de la construction de commandes.
Variables de shell
Pour exemple, nous pouvons assigner la valeur /home/user/work/directory (un chemin absolu donc) à une variable appelée myvar grâce à l’opérateur « =« , et faire appel à cette variable dans d’autres commandes en utilisant le caractère spécial « $« .
Note l’utilisation de la commande echo qui permet d’afficher son argument dans la sortie standard actuelle ou STDOUT (ici, notre terminal).
myvar="/home/user/work/directory"
echo $myvar
ls -al $myvar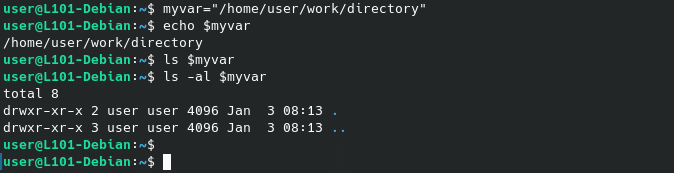
Ce genre de variables sont appelées des variables de shell et ne sont définies (comprendre « accessibles ») que dans la session shell active.
Ces variables seront perdues à la fermeture du shell et ne sont pas accessible dans d’autres sessions.
Pour exemple, ouvrir un autre terminal et essayer de faire appel à notre variable ne fonctionnera pas.
Variables d’environnement
A l’inverse, les variables d’environnement sont définie globalement au niveau du système et peuvent être assignées/appelées depuis n’importe quel session de shell.
Elles sont souvent utilisées pour stocker des informations utiles globalement, tel que le compte utilisateur actuel, les chemins vers les répertoires importants ou le type de shell actuel.
Ces variables peuvent également être assignées par l’utilisateur et c’est une pratique courante pour faciliter l’utilisation de commandes complexes.
Pour obtenir une liste de ces variables d’environnement, utilise la commande env.
env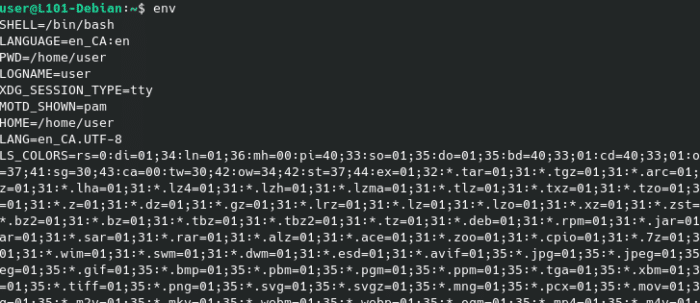
Une variable d’environnement peut uniquement être définie en utilisant la commande export, suivi du nom de la variable.
Note qu’utiliser un nom existant écrasera la valeur, alors qu’utiliser un nouveau nom créera une nouvelle variable.
export myvar
export myvar2="/another/value"Vérifie à nouveau la liste des variables d’environnement pour confirmer les modifications.
env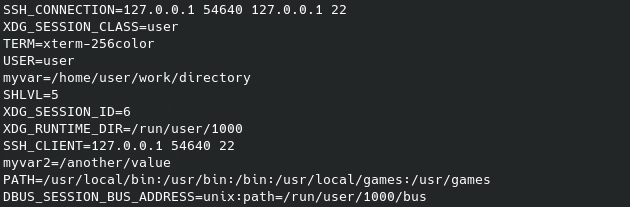
Bonus
- Trouve un moyen de modifier le prompt de ton terminal.
- Est-ce que les variables d’environnement persistent après un redémarrage du système ?
- Comment faire en sorte que des variables définies par l’utilisateur soient disponible même en ouvrant un nouveau terminal, ou après un redémarrage ?
Descripteurs de fichier et Opérateurs
Tu auras certainement déjà entendu que « sous Linux, tout est fichier« … mais c’est un raccourci rapide et peu précis.

Descripteurs de fichier
Sur les systèmes Linux, chaque chose est identifiée par son descripteur de fichier (file descriptor en anglais), que ce soit des équipements physiques (comme une carte réseau), des fichiers ou répertoires réels, ou même les flux d’entrée/sortie des programmes.
Certains de ces descripteurs sont notés de façon particulières, et c’est le cas de STDIN (noté 0), STDOUT (noté 1) et STDERR (noté 2).
Le flux d’entrée standard ou STDIN (noté 0) correspond à tout ce qu’un utilisateur peut saisir et fournir à un programme pour obtenir le résultat voulu, ou dit plus simplement… tout ce qu’il tape sur son clavier lorsqu’il est en mode interactif.
Le flux de sortie standard ou STDOUT (noté 1), lui, correspond à tout ce qu’un programme va afficher comme retour à l’utilisateur lors de son exécution… donc très souvent le résultat attendu.
Et le flux d’erreur standard ou STDERR (noté 2) correspond à… bravo tu as deviné, toutes les erreurs produites par un programme lors de son exécution.
STDOUT et opérateurs
Prenons un exemple concret pour illustrer leur fonctionnement et la syntaxe utilisée avec le descripteur de fichier.
Ici, nous allons utiliser la commande cat, qui permet à l’origine de concaténer plusieurs fichiers (comprendre « ajouter les uns à la suite des autres ») et afficher le résultat via notre sortie standard par défaut (STDOUT).
Comme tu peux le voir, si un seul fichier est donné en argument, la commande permet alors simplement de l’afficher.
cat script.sh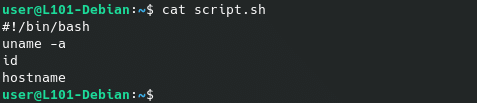
Pour utiliser les descripteurs, nous allons également introduire des opérateurs spéciaux (> et <) qui vont permettre de rediriger les flux d’entrée/sortie de la commande cat depuis/vers un fichier.
Dans l’exemple ci-dessous, nous redirigeons le flux de sortie standard de la commande cat (indiqué par son descripteur 1) dans un fichier texte appelé out.txt.
cat script.sh 1> out.txt
cat out.txt
Notez que l’opérateur > redirige STDOUT par défaut et qu’il n’est pas nécessaire de le spécifier pour obtenir ce résultat.
Vérifions à nouveau le contenu du fichier texte pour observer le résultat, et notez que l’opérateur > écrase le fichier de destination sans avertissement… même si l’exécution de la commande n’a produit aucun résultat (le fichier résultant étant donc vide dans ce cas précis).
cat script.sh > out.txt
cat out.txt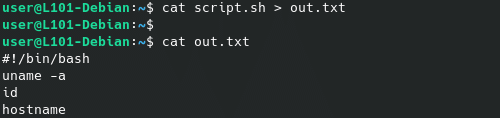
STDERR
Expérimentons maintenant avec STDERR, le but étant de conserver une trace des erreurs lors de l’exécution d’un programme ou d’une commande.
Dans cet exemple, nous allons utiliser la commande grep pour rechercher la chaine de caractère user récursivement (comprendre « en explorant toutes les branches ») à partir du répertoire /root en tant qu’utilisateur standard… ce qui devrait produire une erreur liée aux permissions.
grep "user" /root -r 2> err.txt
Cette redirection du flux d’erreur standard (STDERR) est très courante lors de l’utilisation de commandes ou programmes affichant un nombre très important de messages d’erreur.
Par exemple, si tu utilises la commande grep pour chercher toutes les mentions de la chaine de caractère user dans le répertoire /bin, tu obtiendras énormément d’erreurs indiquant qu’un fichier binaire correspond, sans afficher la donnée qui nous intéresse réellement.
grep "user" /bin -r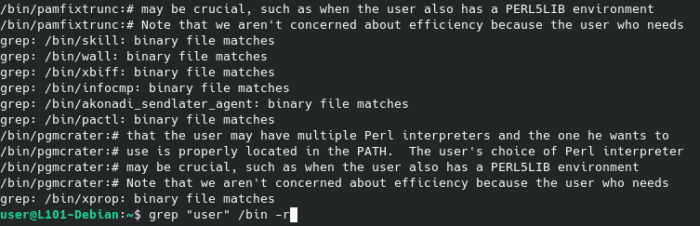
Dans ce cas, rediriger STDERR vers le descripteur /dev/null te permettras de te débarrasser de toutes ces erreurs pour conserver un résultat propre.
Note que /dev/null est un descripteur spécial qui se débarrassera de toute donnée lui étant envoyé… et c’est pour ça que tu le verras parfois mentionné comme vacuum ou blackhole, un concept récurrent autant en système qu’en réseau.
grep "user" /bin -r 2> /dev/null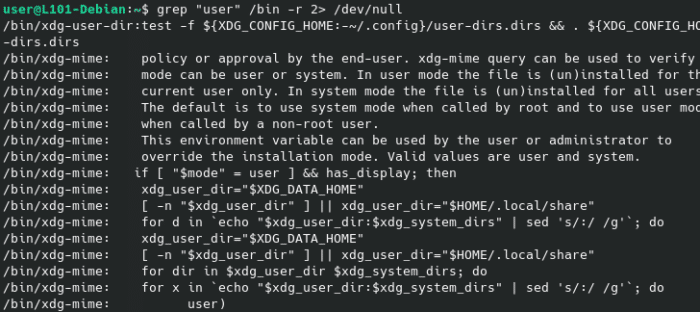
STDIN
Le flux d’entrée standard (STDIN) peut être également utilisé, cette fois avec l’opérateur <, redirigeant alors le fichier spécifié en tant que données saisies par l’utilisateur (habituellement en mode interactif).
Pour préparer cet exemple, enregistre la chaine de caractère suivante…
8743b52063cd84097a65d1633f5c74f5…dans un fichier texte (et pourquoi pas en utilisant la commande echo et un opérateur vu plus haut… ?), puis installe le programme hashid grâce au gestionnaire de paquet apt.
L’installation de paquets nécessite d’avoir des droits super-utilisateur, il faudra donc lancer la commande suivante en tant que root (ou utiliser l’utilitaire sudo, mais nous verrons ça une autre fois).
su root
sudo apt install hashid
exit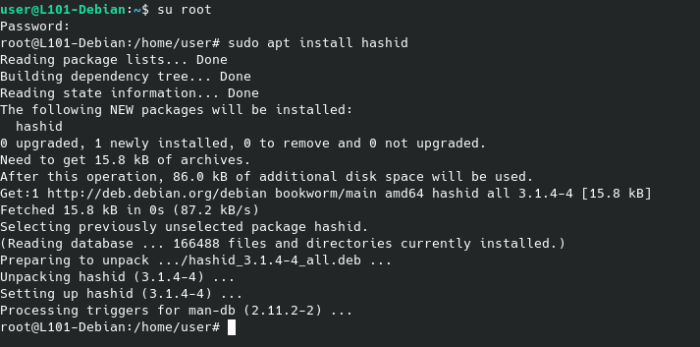
La chaine de caractère vue précédemment est un hash (condensat en français) produit par l’algorithme MD5… et le programme que nous venons d’installer permet justement d’identifier les types de hash possibles en fonction de plusieurs paramètres.
Essaye d’exécuter hashid et observe que sans fournir d’argument, hashid se lance en mode interactif pour nous permettre de saisir le-dit hash.
Quitte le mode interactif en appuyant sur [Ctrl+C].
hashid
test
[Ctrl+C]
Maintenant que tout est prêt, lance hashid en lui fournissant le contenu du fichier hash.txt (c’est à dire le hash qui nous intéresse) via une redirection de STDIN grace à l’opérateur <.
Comme tu peux le constater, le hash est analysé par hashid comme si nous l’avions saisi en mode interactif.
hashid < hash.txt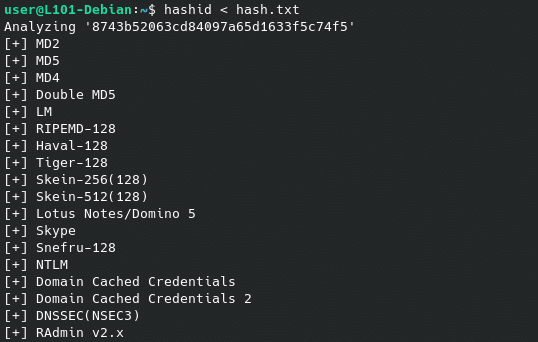
Bonus
- Quels sont les effets et usages des opérateurs <<, >>, &> et <> ?
- Comment faire pour rediriger STDOUT dans un fichier, tout en l’affichant dans le terminal actuel ?
Enchaîner les commandes (Pipes)
Ça se prononce P-AIL-PE, sinon tu passeras pour un(e) dégueulasse, ou au tribunal suivant le contexte.

Pourquoi le Pipe ?
La redirection de flux comme vue ci-dessus est un outil très utile mais il ne permet que d’interagir avec des fichiers, pas de faire communiquer des commandes ou applications entre eux…
Imaginons que nous ayons besoin de supprimer tous les fichiers appartenant à un utilisateur précis.
Avec nos connaissances actuelles, il faudrait d’abord dresser une liste de tous ces fichier, puis les supprimer un par un… pas très efficient comme méthode.
Même si la commande pour effacer les fichiers acceptait une liste en entrée, il faudrait d’abord rediriger la STDOUT de la première commande dans un fichier (avec l’opérateur >), puis rediriger le contenu de ce fichier via STDIN (avec l’opérateur <) dans le second programme, et enfin effacer le fichier pour ne pas laisser de traces inutiles.
Heureusement, des outils bien plus simples et puissants sont à notre disposition… à commencer par le pipe (noté |).
Le pipe est un outil qui permet de rediriger tous les flux (STDOUT, STDIN, STDERR) d’une commande vers une autre, et d’afficher le résultat final à l’utilisateur.
Exemple
Par exemple, si nous voulions détecter le type de hash comme fait précédemment grâce à la commande hashid, il est possible d’utiliser la commande echo avec la valeur souhaitée en argument (ce qui va afficher la valeur via STDOUT) et d’utiliser le pipe pour envoyer le résultat vers la commande hashid.
Note que le résultat de la commande echo ne nous est pas affichée, tout est envoyé au travers du pipe vers la seconde commande.
echo 8743b52063cd84097a65d1633f5c74f5 | hashid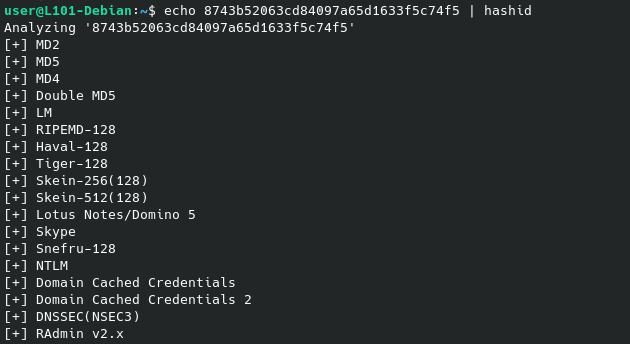
Bonus
- Utilise une combinaison de pipe et d’opérateurs pour stocker le résultat dans un fichier.
- Construis une commande en une seule ligne, utilisant echo, hashid, grep et des pipes pour afficher le résultat suivant :

Construire des commandes complexes
Le pipe est un outil incroyable… mais il a malheureusement aussi ses limitations, et tu l’as peut être déjà compris.
Que se passe-t’il si une commande n’accepte pas d’argument via sa STDIN ?
C’est le cas de la commande rm qui permet habituellement d’effacer des fichiers et répertoires.
Cas typique
Pour illustrer tout ça, créons quelques fichiers que nous allons tenter d’effacer sauvagement.
touch test1
touch test2
touch test3Ok, arrêtons nous une seconde pour constater que si nous voulons créer neuf fichiers avec cette méthode, il y a une perte de temps énorme, et c’est très pénible à faire.
Tant qu’à faire, utilisons une technique de substitution de commande couplée à une boucle for pour accélérer le processus.
for i in $(seq 1 9); do touch test$i; done

Plusieurs choses sont à noter dans cette syntaxe un peu complexe au premier regard…
La boucle FOR
Commençons avec l’utilisation d’une boucle itérative for, qui est un outil extrêmement commun en programmation.
Sans rentrer dans toutes les subtilités, retiens que cette boucle va exécuter la commande se situant entre les mots clés do et done un certain nombre de fois… nombre qui est défini au début de la commande par l’objet qui se trouve après le mot clé in.
Dans ce cas là, il s’agit d’une séquence de nombre allant de 1 à 9, et à chaque itération, la valeur de cette séquence sera stockée dans la variable i, puis réutilisée par la commande située entre do et done via la syntaxe $i.
Illustrons ça avec un exemple, en prenant les premières itérations de la boucle.
Au démarrage de la boucle, la séquence commence à 1 et cette valeur est stockée dans la variable i.
Puis la commande touch test$i est exécutée, mais la variable i est remplacée par sa valeur, ce qui nous donne la commande suivante…
touch test1…puis la boucle revient au début de la boucle for et passe au second élément de la séquence, qui sera le chiffre 2.
Cette valeur est stockée dans la variable i, qui va modifier et exécuter notre commande de la façon suivante…
touch test2Bref, tu as compris, on ne va pas toutes les faire jusqu’à 9.
La substitution de commande
Passons au second élément qui pique les yeux dans cette commande, la génération de la séquence de nombre au démarrage de la boucle : $(seq 1 9).
Ici c’est extrêmement simple, tout ce qui est noté à l’intérieur des parenthèses et précédé d’un caractère spécial $ sera exécuté comme une commande classique AVANT d’exécuter le reste.
Pour vérifier ce concept, utilise directement la commande dans ton terminal et constate qu’elle génère en effet une liste de nombres qui part de la valeur du premier argument et qui va jusqu’à la valeur du second argument.
seq 1 9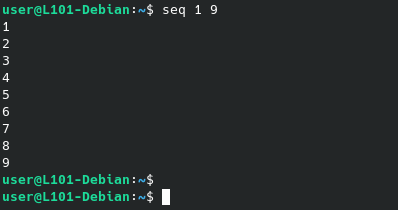
Tu devrais comprendre maintenant, que la boucle for précédente se contente d’exécuter la commande voulue à chaque nouvelle ligne de cette liste de nombres, en remplaçant la variable i par sa valeur actuelle.
C’est bien beau tout ça, mais notre destin de destructeur de fichier nous attends toujours…
Essayons immédiatement notre nouveau pouvoir de substitution grâce à la commande find.
Tu noteras l’utilisation d’une wildcard (*), qui permet d’indiquer que nous acceptons n’importe quel séquence de caractère à partir de cet emplacement.
find /home/user/test*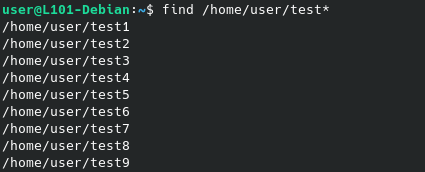
Parfait, nous avons une commande qui fournit une liste de fichier à effacer, il n’y a plus qu’à la donner à la commande rm.
rm $(find /home/user/test*)
Tout a parfaitement fonctionné, mais dans certains cas, par exemple si la commande entre parenthèse génère un résultat vraiment très volumineux, il est possible que ce ne soit pas le cas…
L’alternative Xargs
Heureusement, une autre option est disponible avec l’utilisation de xargs, bien que la syntaxe soit moins intuitive.
Xargs est une commande qui récupère le résultat d’une commande en entrée et l’ajoute en tant qu’argument à une autre, en vous laissant le choix du délimiteur pour traiter l’entrée.
Dans cet exemple, nous commençons par exécuter find pour construire la liste de fichiers, puis utilisons un pipe pour l’envoyer à xargs qui va la découper suivant le délimiteur \n (le caractère spécial indiquant un retour à la ligne), puis fournir cette liste comme argument à rm.
find /home/user/test* | xargs -d "\n" rm
Félicitations, tu es maintenant un destructeur de fichier chevronné !

Bonus
- Trouver une autre syntaxe pour réaliser de la substitution de commande.
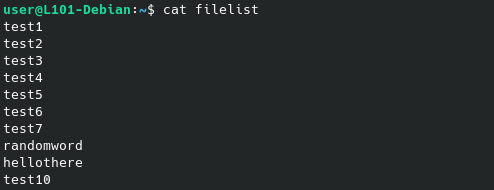
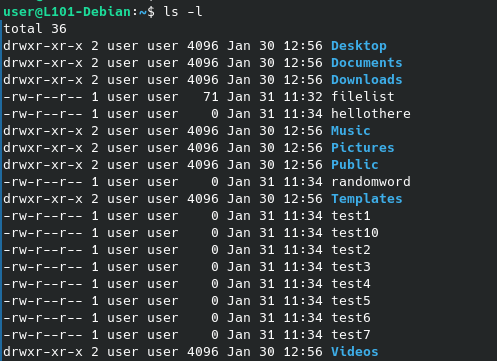
- Dans la boucle FOR utilisée, trouver un moyen de remplacer la séquence de nombre par le contenu d’un fichier.
Pour indice, le contenu du fichier type puis du résultat obtenu par la boucle sont fournis ci-dessous :
La suite c’est par ici !