

Table des matières
Pourquoi ???

Ne pars pas tout de suite !
Ok, le traitement de fichier c’est peut-être pas le cours qui a l’air le plus sexy, mais comme on l’a vu plus tôt, sur Linux tout est configuré ou décrit par des fichiers.
Maitriser la consultation, c’est pouvoir trouver des infos capitales rapidement.
Modifier, extraire, transformer ou combiner ces fichiers, c’est un pouvoir quasi surnaturel qui te permettra de terminer tes projets 10 fois plus rapidement qu’un utilisateur fainéant.
En avant !
Consulter
Head
Si tu suis ces cours dans l’ordre, tu as du apprendre à consulter des logs dans la section précédente, et tu as certainement remarqué que ce genre de fichier est trèèèèèèèèèèèèèès long.
Trop long pour être consulté avec une simple commande cat ou avec un éditeur comme vim ou nano.
La première commande qui pourra t’aider dans ce cas, c’est head, qui permet d’afficher uniquement les premières lignes d’un fichier.
Par défaut, head affichera 10 lignes, mais tu peux spécifier une valeur avec l’option -n.
head /var/log/apt/history.log
head -n 4 /var/log/apt/history.log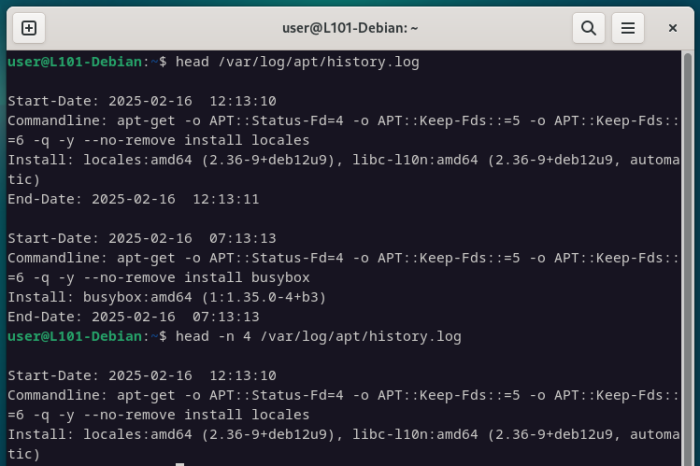
Tail
Est-ce que tu as déjà deviné le but de la prochaine commande ?
Exactement, il s’agit de tail, qui pourra afficher les dernières lignes d’un fichier, toujours avec la même syntaxe que head.
tail /var/log/apt/history.log
tail -n 4 /var/log/apt/history.log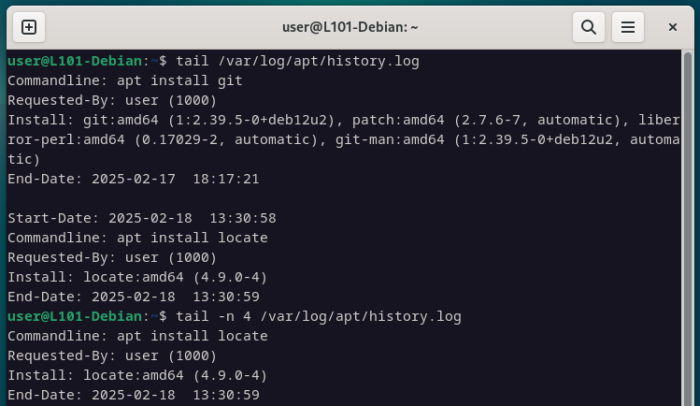
Un autre cas d’utilisation très courant avec tail, c’est celui du monitoring de fichier, souvent des fichiers logs.
Dans le cas où tu aurais besoin de voir en temps réel les évènements apparaitre dans le fichier en question, il est possible d’utiliser l’option -f, qui ajoutera toute nouvelle donnée dans le fichier à ton affichage (STDOUT).
Extrêmement pratique pour suivre des logs en réalisant des tests… essayons ça avec les logs APT (et oui, utilise deux terminaux pour pouvoir suivre en temps réel).
Note que toutes les actions ne sont pas visibles dans les logs… seules les commandes d’installation sont présentes.
Ce n’est pas parce qu’un évènement n’est pas affiché qu’il n’a pas eu lieu, il n’est peut être tout simplement pas pris en compte par les logs.
tail -f /var/log/apt/history.log
sudo apt update
sudo apt install openssh-server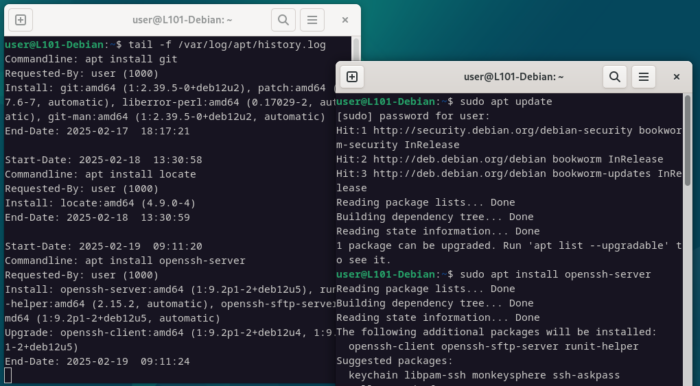
Less
Un autre outil très classique est le pager less.
Un pager c’est un outil qui permet d’afficher et de naviguer dans un fichier texte une page à la fois, grâce à un ensemble de commandes de manière interactive.
Quand les fichiers sont vraiment très grands et qu’on a besoin d’aller chercher quelques informations, ou d’en lire certaines sections au fur et à mesure, sans inonder notre terminal de 5000 lignes, c’est la bonne solution.
Les commandes du mode interactif sont assez intuitives, les flèches [Up] et [Down] permettant de se déplacer d’une ligne, les touches [Page Up] et [Page Down] permettant de se déplacer d’une page entière, et les touches [Home] ou [End] étant également disponibles…
N’hésitez pas à expérimenter ou a trouver la liste des commandes, vu que vous savez maintenant comment obtenir de l’aide en toute autonomie…
less /var/log/apt/history.log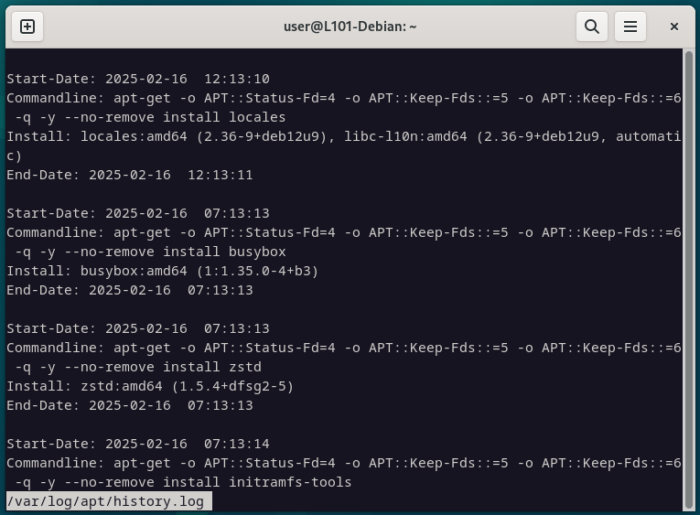
Editer
Nano
C’est certainement le premier éditeur que tu as touché, et c’est un des plus simples à utiliser.
Il est présent de base sur énormément de systèmes Linux et embarque les fonctionnalités de base attendues d’un éditeur… c’est à dire pouvoir écrire ou modifier du texte, et pas grand chose de plus.
Toutes les commandes sont affichées à l’écran lors de l’édition, le symbole ^ indiquant qu’il faut utiliser la touche [Ctrl] en combinaison.
Note que si l’utilisateur actuel n’a pas les droits d’écriture sur le fichier, une note en rouge apparaitra pour prévenir qu’il ne sera pas possible d’enregistrer les modifications.
nano /var/log/apt/history.log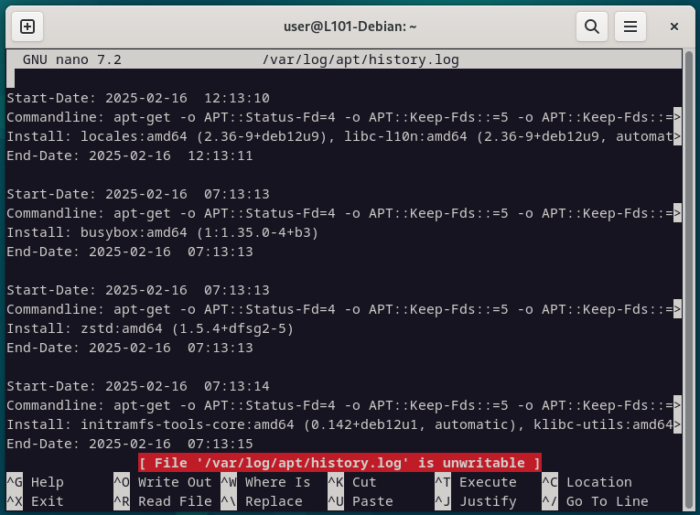
Vim
Visuellement, Vim (ou vi) n’a pas l’air si différent de Nano au premier abord… mais il possède en réalité une batterie de fonctionnalités assez avancées, qui lui permet de rivaliser avec les éditeurs les plus puissants.
Forcément, il pourra paraitre plus complexe à utiliser, mais c’est en réalité une fausse première impression et quelques sessions d’utilisation te feront oublier cette idée.
vim /var/log/apt/history.log
# ou
vi /var/log/apt/history.log
Vim fonctionne suivant un système de Modes, qui permet de séparer les différentes fonctionnalités.
Pour commencer, et il s’agit du Mode activé par défaut, nous avons le Mode Commande, qui fait office de hub central et permet de recevoir des commandes générales ou d’accéder au autres modes.
C’est grâce à ce mode là que tu vas pouvoir naviguer rapidement à travers ton fichier, avec la même logique qu’un pager comme less, et toute la batterie de touches/commandes disponibles.
C’est aussi dans ce mode là que tu pourras utiliser des commandes d’éditions, tel que dd pour supprimer une ligne entière, ou p pour coller du texte en dessous de la ligne sélectionnée, ou encore a pour ajouter une ligne en dessous.
La liste est longue, mais nous te conseillons d’explorer toutes ces commandes et de noter celles que tu trouves intéressantes.
La démarche peut paraitre complexe, mais ce genre d’outil permet d’éditer des fichiers à la vitesse de l’éclair une fois maitrisé.
Pour activer le Mode Edition, il faudra appuyer sur la touche i en étant en Mode Commande.
Déplace le curseur à l’endroit souhaité en Mode Commande et modifie le texte voulu en passant en Mode Edition, puis appuie sur le touche [Esc] pour en sortir.
i
test insert
[Esc]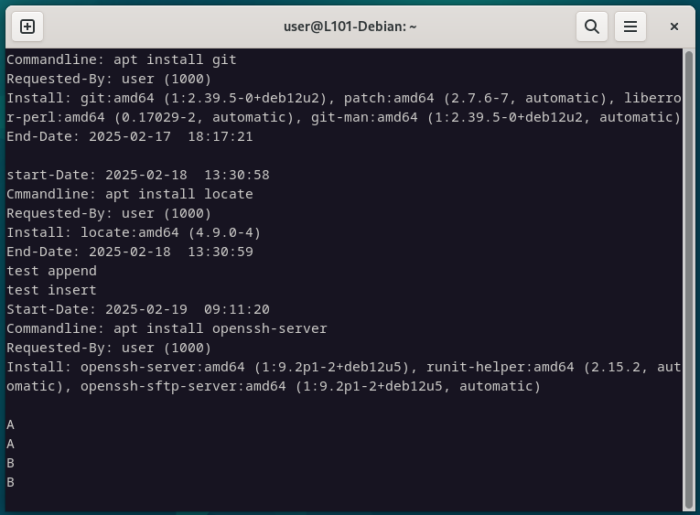
Attention, sortir du Mode Édition n’enregistre absolument pas le fichier sur le disque, tout est encore en mémoire (on verra ça juste après).
Pour finir, le Mode Exécution s’active dès que tu appuie sur la touche [:]
Tous les caractères se situant après ce symbole : seront considérés comme des commandes à exécuter par Vim, un peu à la manière d’option ou d’argument dans un shell bash.
Par exemple, [:]q permet de quitter l’éditeur, [:]wq permet de quitter l’éditeur en enregistrant les modifications, et [:]q! permet de forcer la sortie de l’éditeur sans enregistrer les modifications.
# Quitter
:q
# Sauvegarder et quitter
:wq
# Quitter sans sauvegarder
:q!
Il est également possible d’exécuter des commandes bash directement avec Vim, en utilisant [:]! suivi de la commande souhaitée… ce qui peut être utile lorsqu’on a besoin d’exécuter une commande sans quitter l’éditeur.
:! cat /etc/passwd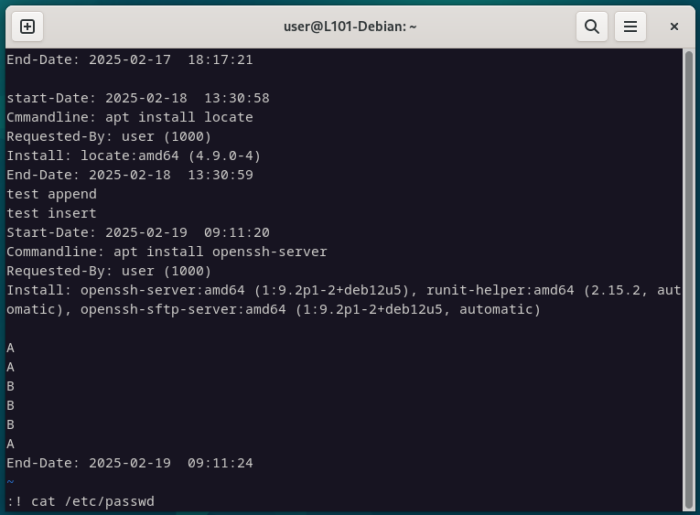
Dans notre cas, cette fonctionnalité n’est pas très utile car nous pouvons simplement ouvrir un terminal à côté, mais dans le cas où notre Linux est installé sans interface graphique, ça le sera.
Vim est un outil à la fois simple à prendre en main, et d’une grande profondeur si tu souhaites explorer toutes ses fonctionnalités…
N’hésite pas à te perdre dans ce rabbit hole !

Bonus
- Trouve un utilisateur de Vim et dit lui que Emacs est le meilleur éditeur, puis résiste à ses assauts plus de 10 minutes.
- Lors de tes prochaines utilisations d’un éditeur de texte, force toi à utiliser Vim et essaye d’utiliser les raccourcis/commandes (cherche une bonne cheat sheet) pour terminer ta tâche en un minimum d’actions.
Combiner
Comme dirait un grand homme, seul c’est fun, mais on s’amuse quand même beaucoup plus à plusieurs !

Combiner des fichiers te servira dans de nombreux cas, soit pour associer des données, soit pour les agréger facilement en un seul fichier.
Les cas d’usages apparaitront d’eux-même au fil de tes aventures, n’hésites pas à ressortir tes notes lorsque ce jour sera enfin arrivé !
Cat
Voici une commande qu’on utilise depuis le début de ces cours… mais dont on a pas encore exploré la réelle fonction.
Cat permet en réalité de d’additionner (concaténer en fait, d’où son nom) deux fichiers et de les afficher dans notre STDOUT, mais si la commande est utilisée avec un seul argument, seul le fichier spécifié est affiché.
Créons deux courts fichiers pour illustrer ça… et constate que les fichiers sont affichés l’un à la suite de l’autre.
echo "text test1" > test1.txt
echo "test test2" > test2.txt
cat test1.txt
cat test1.txt test2.txt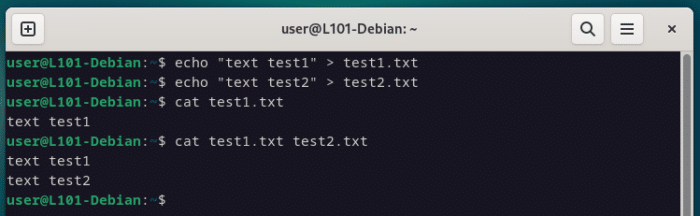
Join
La commande join sera utile dans un autre cas bien précis… celui ou tu as deux fichiers organisés en colonnes, avec des données en commun.
Le cas typique, c’est lorsque tu veux combiner plusieurs fichiers qui contiennent des données associées à des utilisateurs et rangés dans le même ordre.
Join permet de fusionner les données qui sont attribuées au même utilisateur, mais note qu’il faut qu’une des colonnes (ici, c’est la première colonne avec Utilisateur1 et Utilisateur2) soit commune aux fichiers pour que ça fonctionne.
Créé les fichiers avec la méthode que tu préfères et tente de les fusionner.
echo "Utilisateur1 John" > test1.txt
echo "Utilisateur2 Max" >> test1.txt
echo "Utilisateur1 mysecurepassword" > test2.txt
echo "Utilisateur2 mynicepass" >> test2.txt
echo "User1 myoldpassword" > test3.txt
echo "User2 myuglypassword" >> test3.txt
join test1.txt test2.txt
join test1.txt test3.txt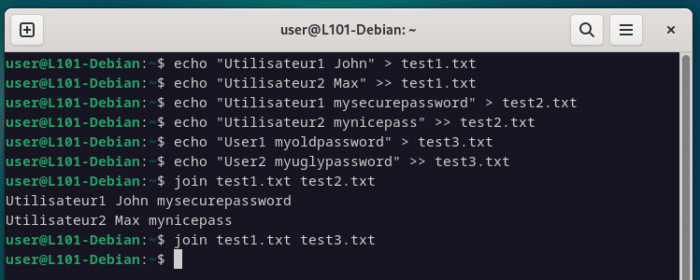
Paste
La commande paste, elle, n’aura besoin d’aucune correspondance et se contentera de coller ensemble les lignes unes par unes.
paste test1.txt test2.txt
paste test1.txt test3.txt
paste test1.txt test2.txt test3.txt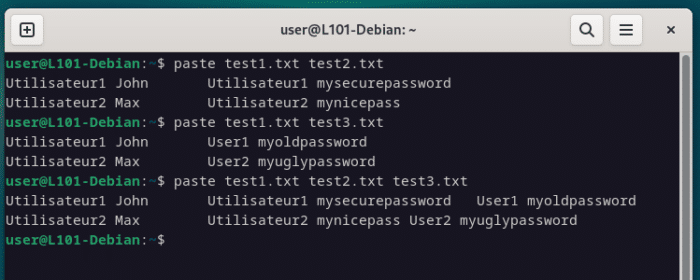
Bonus
- Utilise join pour combiner 2 fichiers qui possède la deuxième ou troisième colonne en commun.
Crée les fichiers à la main si nécessaire.
Transformer
Parfois, les données ne sont pas représentées sous la forme souhaitée pour être traitées par un outil, ou pour être transmises à d’autres services.
Il est donc temps d’apprendre à les T-T-T-T-T-TRANSFORMER !

Od, Xdd et base64
Certains outils te fourniront (ou n’accepteront) que des fichiers sous forme binaire, octale, hexadécimale ou en base64.
Ici, le principe sera toujours le même et la donnée ne fera que changer la façon dont elle est représentée.
Ce principe s’appelle également l’encodage, mais on explorera ça un peu plus tard.
Retiens simplement que le contenu du fichier n’est pas modifié, seule sa forme l’est.
On commence par expérimenter avec la commande od, qui permettra une conversion en format octal, et au passage, familiarise toi avec la commande file qui permet d’obtenir des informations sur le type de fichier.
echo "dis is gud data my fren" transform.file
file transform.file
od transform.file
od transform.file > octal.file
file octal.file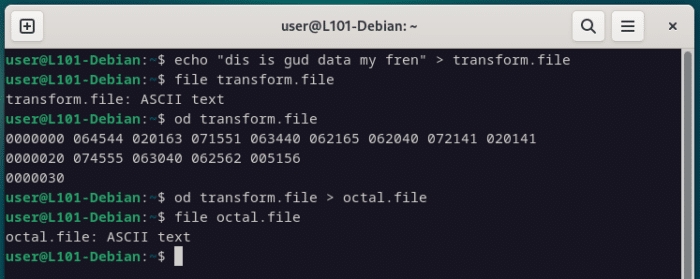
Ok, la commande file indique qu’il s’agit toujours d’un fichier texte encodé en ASCII… sous forme octale.
Et ça confirme ce qu’on avait dit plus haut… seule la représentation change.
En tout cas la forme du fichier a bien été modifié et la donnée est bien représentée en octets, donc avec des valeurs de 0 à 7.
Passons rapidement sur les commandes xdd et base64 qui permettent respectivement de convertir nos données en format hexadécimal et base 64.
sudo apt install xxd
xxd transform.file
base64 transform.file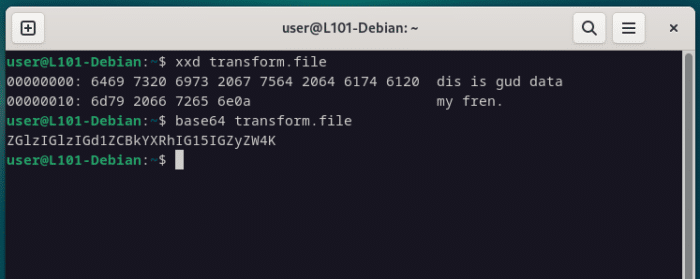
Sort et Uniq
On continue avec deux outils qui vous permettrons de filtrer et ordonner des fichiers assez longs.
Sort est une commande qui permet simplement de trier les lignes d’un fichier en fonction d’un paramètre précis, l’ordre alphabétique par défaut.
Utilisons le fichier /etc/passwd pour illustrer leur usage.
cp /etc/passwd .
sort passwd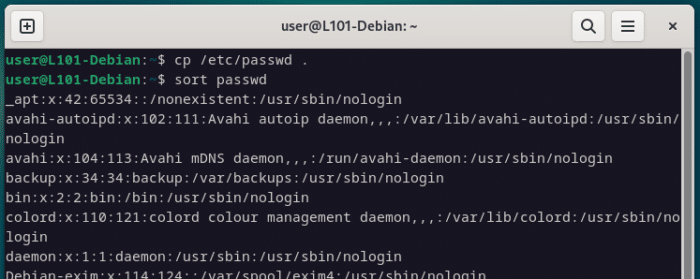
Il possède également une option -u qui lui permet de s’assurer que chaque ligne est unique, éliminant tous les doublons présents.
Uniq est son cousin proche et permet, lui, d’éliminer les doublons uniquement, sans trier quoi que ce soit.
Tu peux l’utiliser à la place de l’option -u de la commande sort au travers d’un pipe, ou seul s’il n’est pas nécessaire de trier les lignes.
cat passwd passwd > doublepwd
sort doublepwd > doublepwdsorted
head -n 4 doublepwdsorted
sort -u doublepwd > doublepwdsortedwithu
head -n 4 doublepwdsortedwithu
sort doublepwd | uniq > doublepwdsortedpipeuniq
head -n 4 doublepwdsortedpipeuniq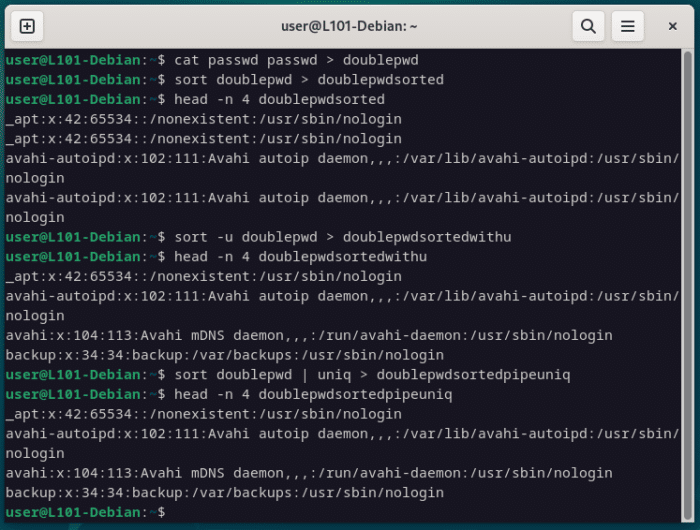
Tr
Parfois, tu tomberas sur un fichier avec un caractère gênant ou que tu as envie de transformer systématiquement.
Pour faire ça simplement, la commande tr sera parfaite.
Spécifie en premier argument le set de caractères à traduire, puis en second argument, le set de caractère qui les remplacera.
Chaque caractère traduit sera attribué dans l’ordre, donc dans l’exemple suivant, les a deviendront des d, les b deviendront des e et les c deviendront des f.
tr abc def < passwd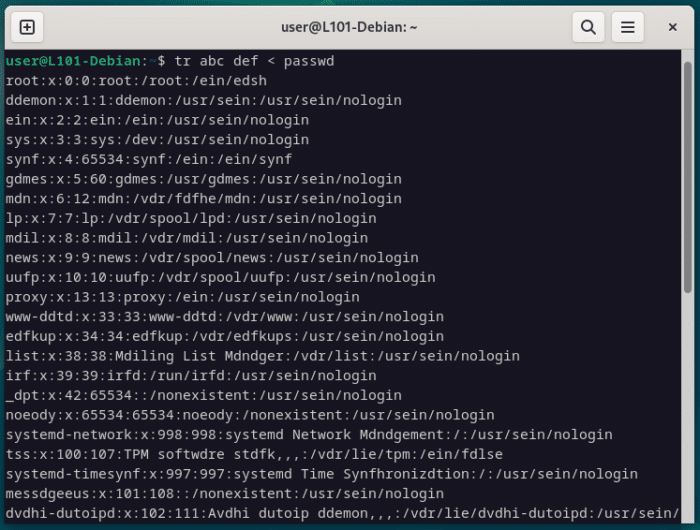
Note que tr peut également être utilisé comme un quick hack pour effacer n’importe quel caractère dans une fichier.
Attention à bien positionner l’option -d avant le caractère ciblé, sinon tr considèrera l’option comme le caractère remplaçant.
tr -d r < passwd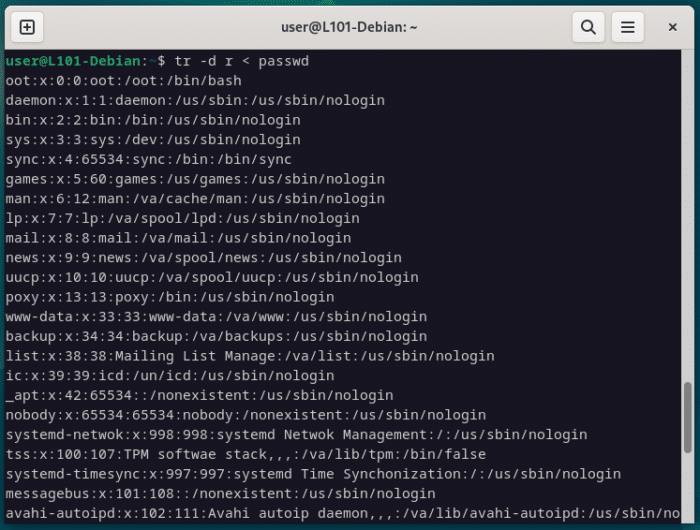
Sed
Avec sed, on arrive enfin dans la cours des grands…
C’est un outil d’édition de fichier vraiment puissant (dans la même veine que awk, que tu pourras explorer en solo), et qui te permettras de faire réellement ce que tu veux de tes fichiers… sous condition de maitriser la syntaxe parfois un peu spéciale.
Pour la syntaxe basique, tu remarqueras que le texte à remplacer se trouve dans le premier espace entre slashs //, puis que le texte remplaçant se trouve dans le second espace.
La lettre s positionnée au début indique qu’on sera en mode substitution, donc qu’on va remplacer la première chaine de caractère par la seconde.
sed 's/root/Lotus/' passwd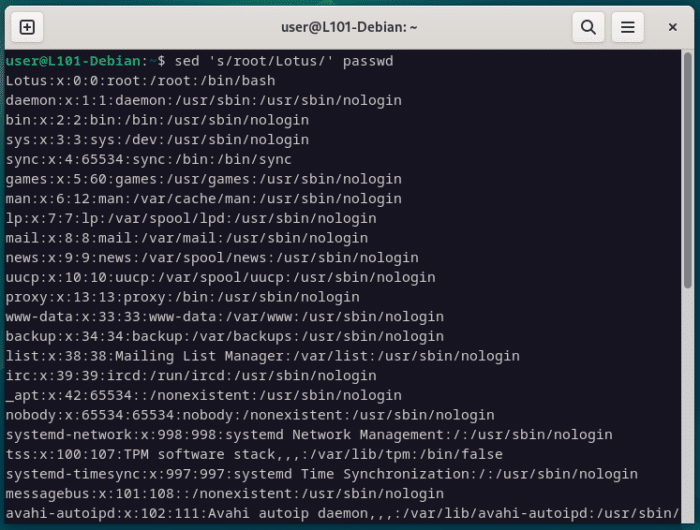
Ici, tu notes directement une différence avec les autres outils, car seule la première apparition du texte « root » a été remplacé par « Lotus » et non la totalité.
Pour modifier toutes les occurrences, il faudra ajouter le caractère g à la fin de la syntaxe, ce qui activera le mode d’édition dit global.
sed 's/root/Lotus/g' passwd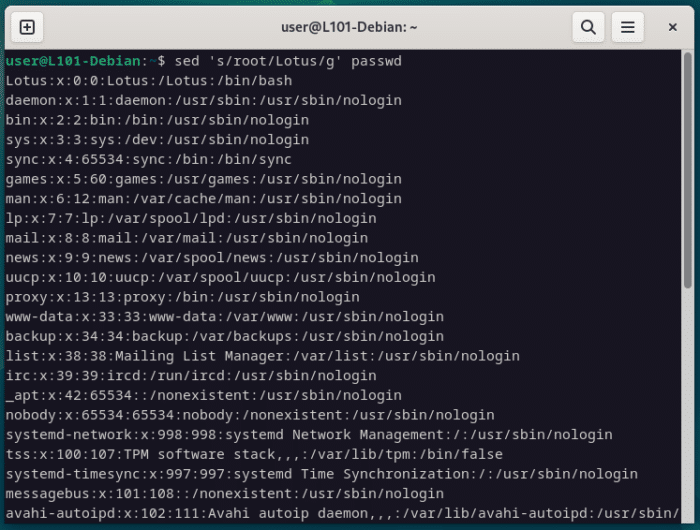
Une autre utilité de sed sera de supprimer des lignes entières via leur numéro, soit une par une, soit une plage complète, avec la notation d pour effacer, le point-virgule (;) comme séparateur et la virgule (,) pour indiquer une plage.
sed '1d;3d;6d' passwd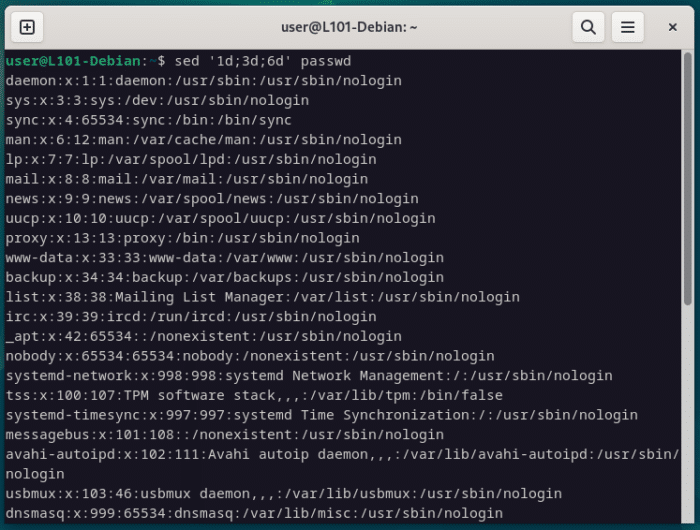
sed '1,6d' passwd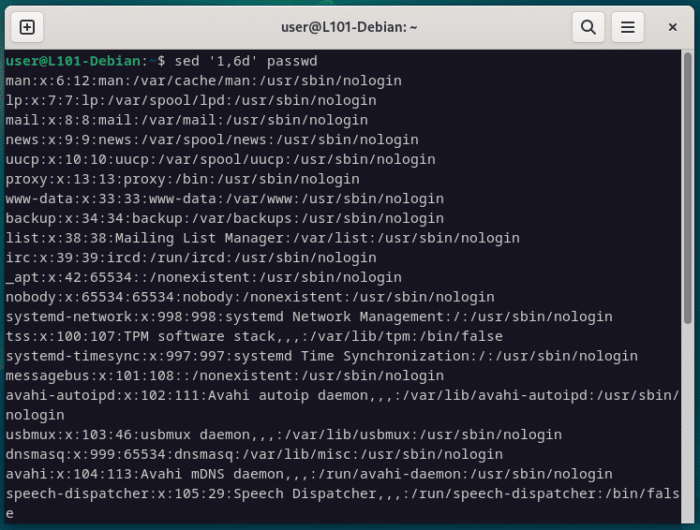
Sed est un outil incroyablement complet et les options sont nombreuses.
Il ne sera pas possible de toutes les explorer ici, mais à chaque fois que tu as une édition de fichier à faire, lance une recherche pour voir comment (et pas « si ») sed est capable de réaliser tes souhaits.
D’autant plus qu’il est possible de la combiner avec des expressions régulières (regex), mais on pourra voir ça un peu plus tard.
Bonus
- Fait des recherches sur la notion d’encodage et tente de noter les différences entre le Base 64, l’ASCII et l’Unicode (UTF-8 et UTF-16).
- Explore les autres modes disponibles de sed (hors expression régulière/regex) et trouve comment modifier un fichier directement (sans utiliser d’opérateur).
Extraire
Cut
Parfois, tu auras simplement besoin d’extraire une information précise d’un fichier, sans avoir de réel contrôle sur le contenu lui-même…
Par exemple, imagine que tu aies besoin de construire une liste des utilisateurs présents dans le fichier passwd.
A chaque ligne, le nom d’utilisateur change et la longueur varie, donc pas possible de les extraire via un certain nombre de caractère depuis le début de la ligne… ou via une correspondance quelconque.
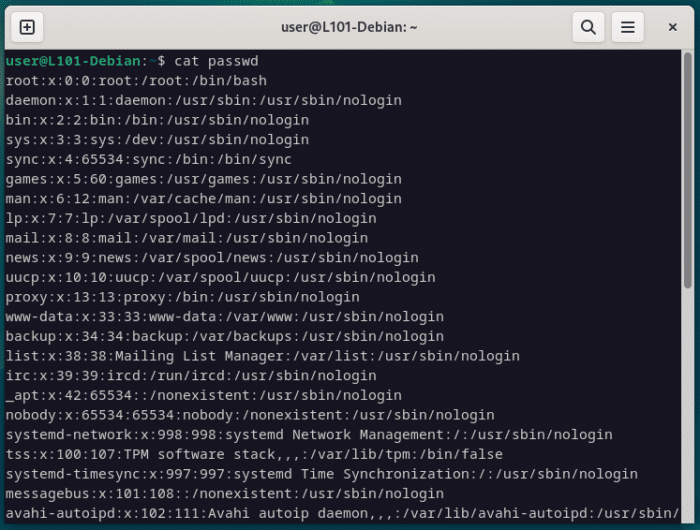
Par contre ce qu’on remarque, c’est que chaque nom d’utilisateur est suivi d’un caractère spécial (:), qui est en réalité un délimiteur de colonne.
A ce moment-là, la commande cut devient l’outil parfait.
Cut te permet de définir un délimiteur de ton choix avec l’option -d, puis de sélectionner un champ avec l’option -f, numéroté en fonction de ton délimiteur.
Par exemple, pour ce fichier passwd, si le caractère : est le délimiteur, alors le premier champ sera le nom d’utilisateur, le second sera le caractère x, le troisième sera l’UID, le quatrième le GID, etc…
cat passwd | cut -d ':' -f 1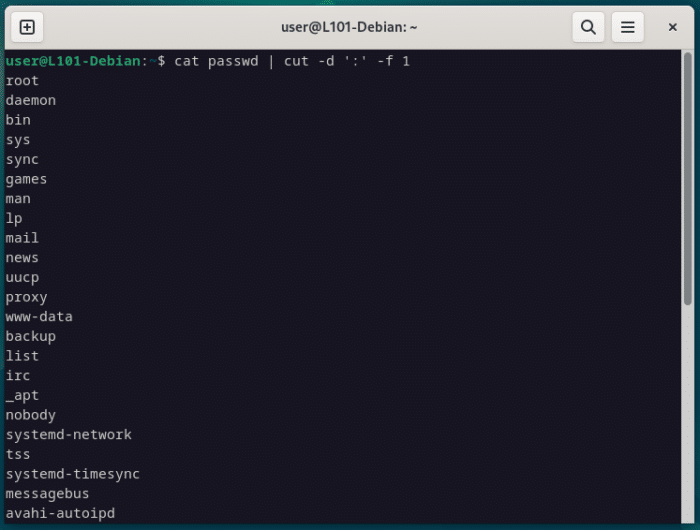
Note qu’il est possible de définir n’importe quel caractère en délimiteur, même un espace ou un caractère spécial.
cat passwd | cut -d '/' -f 2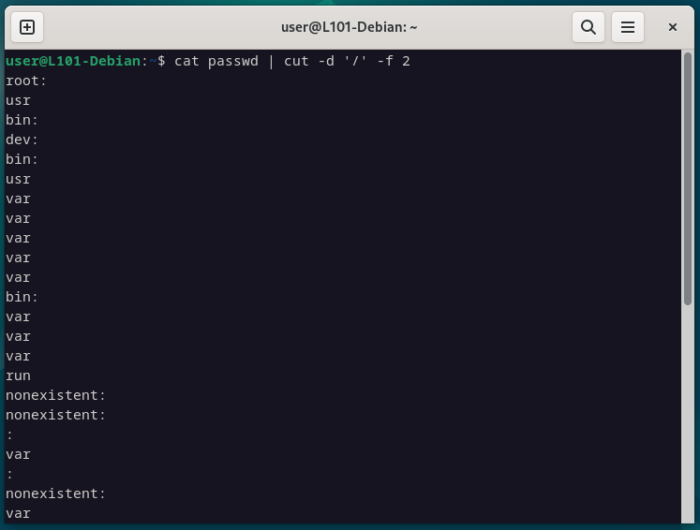
Grep
Un autre outil très fréquemment utilisé sera grep, qui permet de rechercher des chaines de caractères spécifiques dans un ou plusieurs fichiers.
Grep tire son utilité des très nombreuses options disponibles, de la capacité à effectuer des recherches récursives avec -r ou -R (donc d’explorer des branches entières du système de fichier comme le fait find) et de sa capacité à utiliser les expressions régulières pour une recherche très précise.
L’utilisation basique se fait en indiquant la chaine de caractère à chercher, suivi du fichier cible.
Note que lors d’une recherche retournant plusieurs résultats, le chemin absolu du fichier est indiqué en début de ligne, puis la ligne concernée est affichée après le séparateur (:).
grep "root" passwd
grep "root" -R /etc/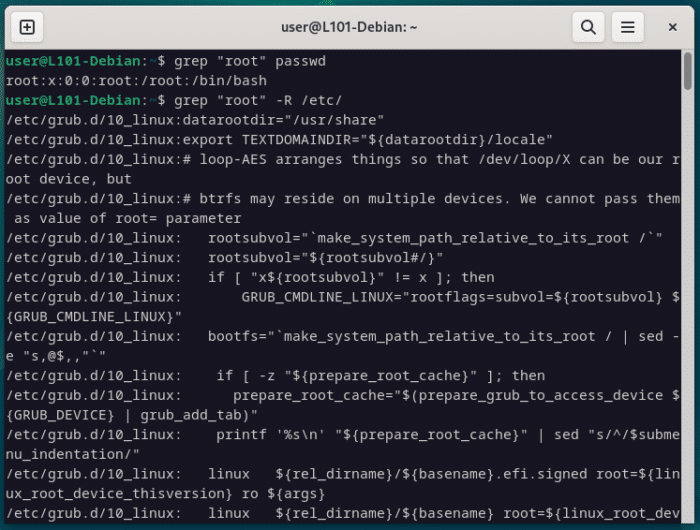
Bonus
- Utilise la commande cut pour arriver à extraire le nom de groupe pour chaque utilisateur depuis le fichier /etc/passwd, en une seule ligne de commande (pipe autorisé et conseillé).
- Trouve les options de grep pour afficher les lignes précédentes et suivantes de chaque résultat.
- Explore les options de grep pour arriver à faire une recherche insensible à la casse et qui ne retourne que les résultats qui ne correspondent pas à ta recherche.
Les expressions régulières (regex)
Bienvenue dans la section consacrée aux REGEX !
Tu as l’impression qu’on a éternué sur ton clavier et tes yeux fondent à la lecture de ces CHARMANTES écritures ?
Tu n’as pas étudié tous les chapitres précédents pour préparer un doctorat en hiéroglyphes ???
Ne t’inquiète pas, nous non plus , et oui, on a aussi envie de se crever les yeux…
Mais reste avec nous et installe-toi confortablement, on va t’aider à traverser cette épreuve.
Principe
Les regex viennent d’un besoin assez simple… comment faire pour intégrer un système de logique dans de la recherche de texte ?
En langage humain, c’est plutôt simple après tout.
Si je te demande de m’extraire tous les mots qui se situent en fin de ligne et se terminent par « ers », tu n’auras aucun problème à comprendre.
Idem si je te demande d’extraire tous les mots se finissant par « tion »…
Mais comment faire pour demander ça à une machine, sans qu’il n’y aie de confusion ou d’erreur ?
C’est ici qu’interviennent les regex (ou expression régulières en français), et il s’agit en fait d’une syntaxe qui permet d’énoncer ces règles logiques.
Commençons avec le début et fin de ligne, noté respectivement ^ et $.
Dans ce cas, si j’écris ^root, la regex se traduit par le mot root situé en début de ligne, et si j’écris root$, la regex se traduit par le mot root situé en fin de ligne.
^root
root$Une autre syntaxe très courante est le point (.) qui indique n’importe quel caractère et qui peut être couplé avec l’étoile (*) pour indiquer une chaine de caractère avec n’importe quel caractère et de n’importe quelle longueur.
Dans ce cas, l’expression régulière root.* indique le mot root suivi de n’importe quelle séquence de caractère et de n’importe quelle longueur, ou plus simplement tout ce qui commence par root.
root.*Ajoutons un dernier élément très important, les listes.
Jusqu’à maintenant, la chaine de caractère était très spécifique, mais il est possible que j’ai envie d’extraire des choses plus générales, comme tous les mots de 4 lettres qui commencent par une majuscule.
Dans ce cas, il est possible d’utiliser des listes de caractères entre crochets pour indiquer les possibilités, par exemple [ABCDE] qui correspondra à A, B, C, D, ou E en majuscules, ou d’indiquer une plage entière grâce au tiret placé entre deux valeurs, par exemple [A-Z] qui correspondra à toutes les lettres majuscules de A à Z.
Prenons un exemple, qui correspondra à 4 lettres dont la première en majuscule et suivi d’un chiffre.
Note qu’on retrouve bien 5 ensembles de crochet, donc un par caractère, avec à chaque fois la plage de possibilité recherchée.
Ici, la chaine de caractère Lotu4 correspondra, Noob0 également, mais pas Fatou, ni lalu4.
[A-Z][a-z][a-z][a-z][0-9]Dernier point avant de passer à la pratique…
Il est possible de créer des combinaisons très complexes avec ce genre de règles, mais se perdre dans les embranchements logiques et aussi assez probable en augmentant la complexité.
Beaucoup de cheat sheet et de sites permettant de vérifier l’effet de tes regex sont disponibles, alors utilise-les régulièrement et graduellement pour diagnostiquer d’éventuels problèmes.
Source : https://regex101.com/
Exemple avec Sed
Ok, fini de jouer, cette fois on va sortir une vraie regex bien sale et se faire fondre les yeux.
Sed avec son option -E permet de prendre en compte les expressions régulières étendues (wut?), ce qui nous donne un outil redoutable.
Dans cet exemple, nous allons utiliser le mode d (pour delete) de sed, permettant d’effacer toute correspondance avec notre regex.
Pas de substitution cette fois, donc tout ce qui correspond à l’expression placée entre les deux slashs sera effacé directement.
La syntaxe va être velue une fois la regex positionnée, donc voici un prototype vide de la commande pour comparaison.
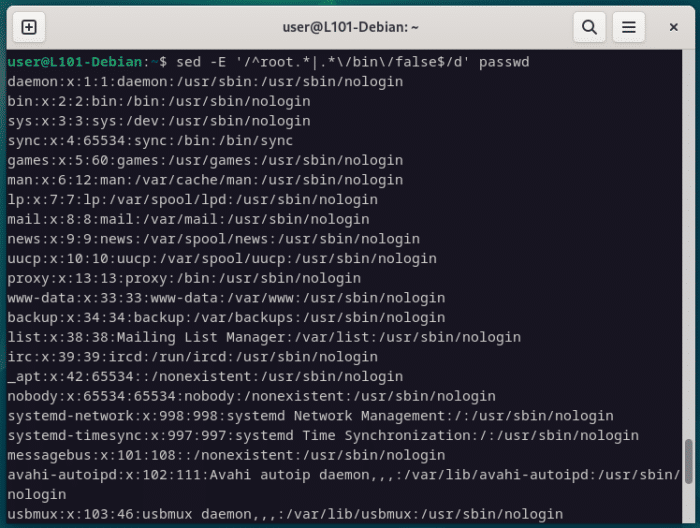
sed -E '/REGEX-ICI/d' passwdEt voici la vraie commande avec la regex correspondante…
sed -E '/^root.*|.*\/bin\/false$/d' passwdOk, effectivement on y comprend rien les premières fois… il va falloir décomposer.
La première chose à remarquer, c’est qu’il y a deux nouveaux opérateurs qu’on avait pas rencontré avant, l’antislash (\) et le pipe (|).
Le pipe (|), lui, est l’opérateur OU, qui indique donc que notre regex pourra correspondre SOIT à la partie située avant le pipe (donc ^root.*) , SOIT à la partie située après (donc .*\/bin\/false$).
La première section (^root.*) devient donc compréhensible et correspondra à toutes les lignes commençant par root.
Passons à la seconde partie et commençons par éclaircir l’utilité de l’antislash.
Comme tu peux le voir, le slash est déjà utilisé par sed pour délimiter le début et la fin de son argument (sed -E ‘/ /d’ passwd), donc toute la syntaxe de sed se brise si on utilise des slashs bruts dans la regex.
La fin de cette regex essaye de trouver une séquence qui correspond à /bin/false, mais les slashs du chemin absolu seront interprétés par sed si laissés seul, il faut donc tous les échapper avec un antislash, d’où la syntaxe \/bin\/false… et si on prends en compte le reste, ça nous donne toute ligne finissant par /bin/false.
Donc, pour résumer ça en termes humains, sed va rechercher toute ligne commençant par root OU finissant par /bin/false et l’effacera du fichier ciblé.
Exemple avec Grep
La commande grep, déjà très utile seule, devient encore plus puissante une fois les expressions régulières maitrisées.
Si sed te permet de modifier tes fichiers à l’envie, grep te permettra de trouver ou d’extraire n’importe quelle chaine de caractère.

Il n’y a aucune différence dans la façon d’utiliser les regex entre sed et grep… ou tous les autres outils d’ailleurs, et c’est une des forces principales de ce système.
On te laisse le soin de décomposer et comprendre la regex suivante…
BON CHANCE
grep -e -R ".*[0-9][a-Z0-9]$|user.*[5-7]$" /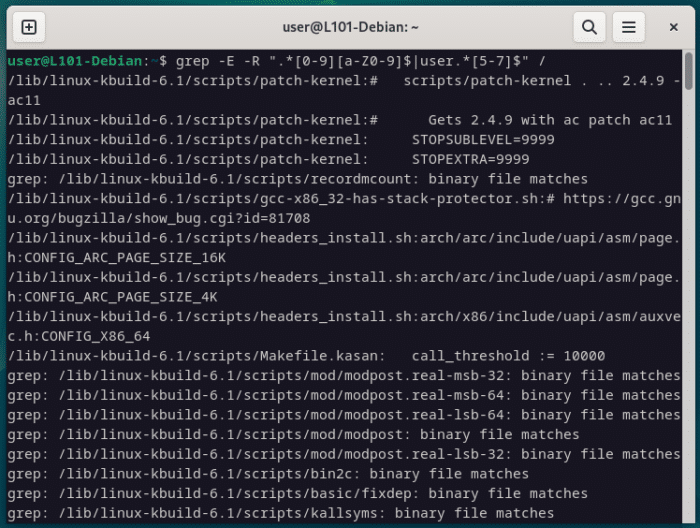
Bonus
- On sait très bien que t’as pas encore trouvé la réponse à la dernière regex, remonte et explique-la en termes simples.
- Fixe toi 3 objectifs de recherche oralement et essaye d’écrire la correspondance en regex.
- Trouve un autre outil très performant pour effectuer des recherches sur ton système et qui supporte également les regex.
- Il y a une chance sur deux que tu n’aies rien compris mais que tu cliques ici pour passer au chapitre suivant… REMONTE ET TERMINE !
- Non vraiment, sans blaguer, c’est difficile pour tout le monde mais extrêmement utile, alors courage.
La suite c’est par là !